
Recherche en cours : le Model Checking, pour les explorateurs de systèmes !
Si, pour le commun des mortels, il est difficile de trouver le point commun entre un Rover explorant Mars, le métro parisien et un Rubik’s Cube, ce n’est pas le cas des spécialistes du Model Checking (ou vérification de modèles), en particulier les chercheurs du Laboratoire de Recherche et Développement de l’EPITA (LRDE), qui vous diront que chacune de ces entités représente avant tout un système à explorer.
En marge du nouvel épisode vidéo de la série « Recherche en cours, EPITA Laboratoire d’innovation » consacré cette fois au logiciel SPOT développé au sein de l’école, Alexandre Duret-Lutz, enseignant-chercheur à l’EPITA et responsable de l’équipe Automates & Vérification au sein LRDE, prend le temps de revenir sur ce qui fait du Model Checking une approche incontournable aujourd’hui pour la recherche en informatique !
En quoi consistent vos travaux sur le Model Checking ?
J’essaye tout simplement de vérifier le comportement des systèmes. Un système peut être n’importe quoi – un Rubik’s Cube, un programme, une machine à laver, un métro… –, mais chaque système possède son propre comportement dans le temps. Mon travail consiste justement à envisager tous les futurs possibles d’un système afin de vérifier que, pour chaque branche de ces futurs, tout se passe bien. C’est un peu comme les crash-tests dans le monde automobile, où l’on envoie des voitures percuter un mur pour voir comment elles se comportent, sauf que ces crash tests représentant un certain coût, ils ne permettent pas de tester tous les scénarios possibles. D’où l’intérêt du Model Checking !
Comment cela fonctionne en théorie ?
Si l’on veut aller plus loin dans l’explication, on peut prendre l’exemple du Rubik’s Cube. Il a sa configuration de départ et permet de faire telle ou telle rotation pour changer de configuration. Ces rotations sont ce qu’on appelle des « événements » : ils arrivent sur le système et le modifient. Dès lors, on peut donc très bien s’imaginer un « arbre » de tous les futurs possibles, doté de multiples branches qui, à l’inverse d’un arbre classique, ne sont pas séparées, dans le sens où elles finissent par se rejoindre – il y a plusieurs façons de tourner un Rubik’s Cube pour revenir à une même configuration. On sait que l’ensemble des configurations que l’arbre du Rubik’s Cube peut atteindre est fini – pour le Rubik’s Cube 2x2x2, on dénombre environ 3 millions de configurations (ou d’états, autre terme employé). Avec le Model Checking, le but est d’alors représenter ces 3 millions de configurations sous la forme d’un « automate », soit un arbre dont on aurait plié les branches pour qu’elles se rattachent là où les configurations finissent par être identiques, puis de créer des algorithmes capables de se balader dans ces 3 millions d’états. Ainsi, ces algorithmes peuvent explorer tous les chemins potentiels à partir d’une configuration donnée pour y vérifier les propriétés qui nous intéressent. Dans le cas du Rubik’s Cube, les propriétés qui peuvent nous intéresser sont, par exemple, de savoir si, à partir de telle ou telle configuration, on peut résoudre le cube en moins de N mouvements. Si, à la place d’un Rubik’s Cube, on prend le cas d’une ligne de métro, cela pourrait être de savoir si un passager entrant réussira à en sortir. Voilà ce qu’est le Model Checking : faire un modèle du système, explorer l’automate (soit l’arbre des futurs replié) et donc tous les comportements du système pour, sur tous ces comportements, vérifier des propriétés de sécurité. De fait, et pour revenir à l’exemple du Rubik’s Cube 2x2x2, les 3 millions de configurations décrivent une infinité de chemins de longueur infinie – c’est l’une des particularités de ce casse-tête : on peut toujours tourner ! Le Model Checking va nous permettre de vérifier que tout se passe bien sur l’intégralité de ces chemins sur l’ensemble des comportements possibles.
Pourquoi la recherche est-elle essentielle à ce sujet ?
Si je passe à plus gros Rubik’s Cube comme la version classique de taille 3x3x3 – mais il en existe de plus gros –, je dois alors représenter 4×10¹⁹ configurations, ce qui ne rentrera pas dans la mémoire d’un ordinateur classique. Il me faut alors inventer d’autres techniques plus poussées pour représenter mon automate afin qu’il tienne dans cette mémoire. C’est un problème dans le Model Checking qu’on nomme « l’explosion de l’espace d’états » : plus les systèmes que l’on souhaite vérifier sont gros, plus on avoir de mal à représenter l’ensemble de leurs configurations possibles en mémoire. On comprend alors que, selon la nature du système, les techniques de Model Checking vont différer. En ce qui me concerne, je travaille sur des systèmes qui sont plutôt des systèmes dits « parallèles », avec parfois plusieurs processus qui tournent en même temps sur un ordinateur tout en s’échangeant des messages. On peut ainsi modéliser des protocoles de communication, comme un client qui souhaiterait parler à un serveur – il enverrait une requête, le serveur lui répondrait et nous, on vérifierait que quelle que ce soit la requête envoyée, une réponse serait reçue dans le futur. On peut aussi vérifier des protocoles de cryptographie, pour éviter les éventuelles failles si X veut envoyer un message à Y et que Z veut intercepter le message. Au sein du LRDE, nos recherches consistent plus largement à améliorer toutes les techniques utilisées dans le Model Checking, notamment pour trouver comment représenter plus efficacement encore cet immense espace d’états en partageant la mémoire et en compressant les données, comment explorer beaucoup plus rapidement cet espace d’états en ignorant certains chemins et comment représenter les propriétés du système.
Qui utilise les techniques de Model Checking ?
Comme il permet d’analyser l’intégralité des comportements, l’un des intérêts du Model Checking est donc de pouvoir modifier un système pour le corriger quand on trouve un comportement qui ne respecte pas la propriété de sécurité que l’on souhaite vérifier. De ce fait, parmi les utilisateurs réguliers du Model Checking, on retrouve notamment les personnes qui conçoivent des systèmes critiques, c’est-à-dire des systèmes qui peuvent avoir un impact de vie ou de mort sur l’humain ou d’une importance extrême sur une mission du même ordre. Quand on est à ces niveaux de criticité, il faut faire tout ce qui est en notre mesure pour éviter ces cas de figure. Il faut donc faire avancer la recherche pour être capable de vérifier ces systèmes. Une autre approche voudrait que l’on utilise à la place des systèmes plus simples afin de faciliter ces vérifications, mais la réalité fait que nous sommes plutôt de plus en plus confrontés à l’utilisation de systèmes de plus en plus complexes. Ainsi, à la NASA, plusieurs parties des fusées et robots envoyés dans l’espace ont été vérifiées à l’aide de techniques de Model Checking. Plus la recherche avance et plus les techniques s’améliorent, ce qui est important car, plus le système est gros, plus cela requiert du temps et de la mémoire pour bien le vérifier. Pour certains systèmes, la vérification peut prendre une journée, une semaine, voire jusqu’à plusieurs mois ! Le Model Checking permet de trouver un maximum de bugs – si bug il y a, bien sûr.
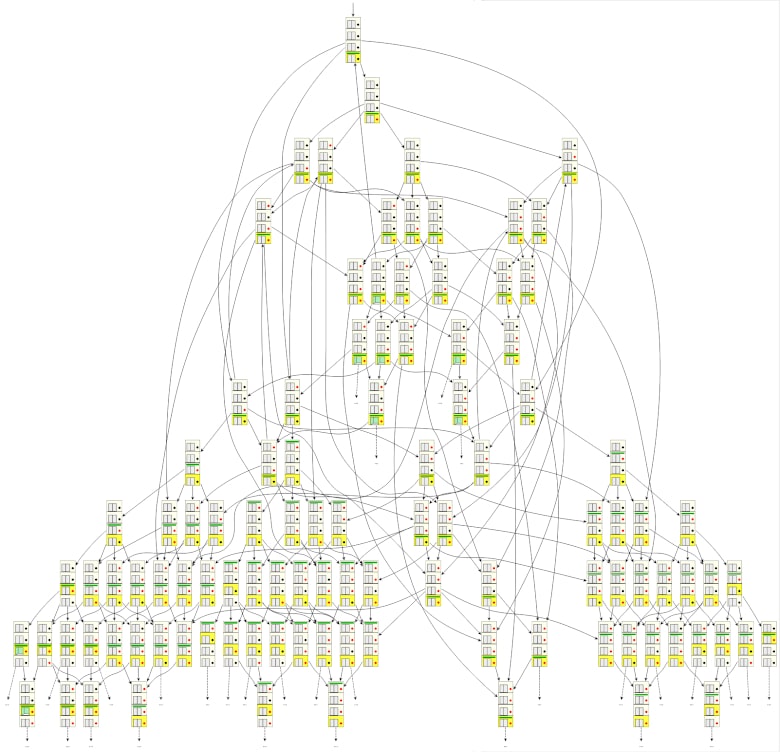
Les 106 premiers états d’un espace d’états pour un petit modèle d’ascenseur (qui en compte normalement 352) permettent de mieux visualiser l’intérêt du Model Checking
Qu’est-ce qui vous passionne dans la recherche ?
Sans doute toutes les interactions avec les autres chercheurs du monde académique. En effet, de nombreuses équipes de recherche travaillent sur le sujet du Model Checking, comme par exemple celle de l’Université de Brno, en République Tchèque, avec laquelle nous entretenons un rapport privilégié et qui partage vraiment nos centres d’intérêt, notamment sur l’aspect automate. J’ai ainsi pas mal de collègues à l’étranger, qui travaillent sur des sujets connexes aux miens, et je sais qu’ils n’hésitent pas à s’appuyer sur les algorithmes que je développe. Nous collaborons également parfois sur l’élaboration de certains algorithmes. Ces échanges sont toujours enrichissants, d’autant que la recherche en Model Checking ne s’arrêtera jamais : nous serons toujours en quête de techniques permettant d’aller plus vite, de prendre moins de mémoire et de vérifier des systèmes et modèles de plus en plus complexes.
En parlant d’échanges, au sein du LRDE, vous accueillez aussi parfois des EPITéens pour mener différents projets.
C’est vrai ! En ce moment, je travaille avec un étudiant de l’EPITA qui cherche à optimiser une technique pour réduire les automates servant à représenter les propriétés que l’on souhaite vérifier. Pour cela, il cherche à implémenter de la manière la plus efficace possible un algorithme développé par une autre équipe de recherche. Travailler sur ce sujet lui permet d’apprendre de nouvelles choses tout en contribuant à SPOT, notre logiciel libre dans lequel nous implémentons toutes nos techniques. Cela lui donne l’occasion de découvrir à la fois le monde du Model Checking et celui des automates, mais aussi de se plonger dans la recherche, en se familiarisant avec le quotidien des chercheurs, en apprenant à lire et utiliser des publications scientifiques… Évidemment, les étudiants qui nous rejoignent peuvent aussi nous apporter un autre regard, de nouvelles idées pertinentes. La recherche se nourrit aussi de ces moments !
Le logiciel SPOT jouit justement d’une belle réputation aujourd’hui. Est-ce un motif de fierté ?
Bien sûr ! Toutes les techniques de Model Checking sur lesquelles nous travaillons, nous les implémentons ensuite dans SPOT, un logiciel libre diffusé sur le site du LRDE. N’importe qui peut le télécharger et l’utiliser comme bon lui semble, mais aussi contribuer éventuellement au logiciel en apportant de nouvelles fonctionnalités. Aujourd’hui, je suis très fier de voir SPOT être utilisé par de nombreuses personnes à travers le monde, qui s’en servent pour construire des choses encore plus compliquées ! Ce logiciel, c’est comme mon bébé, même si je ne suis pas son seul auteur – des collègues et des étudiants travaillent aussi dessus collectivement. SPOT est reconnu par la communauté. Recevoir des retours sur le logiciel et voir ce que les gens en font nous donnent toujours plein d’idées pour améliorer l’outil. C’est une dynamique qui plaît beaucoup !
